on
The fine line between mistake and innovation in LLMs
 Imaginary artwork, combining elements of unknown and excitement, generated with DiffusionBee.
Imaginary artwork, combining elements of unknown and excitement, generated with DiffusionBee.
Table of contents
- Premise
- Hallucinations
- Why do they happen?
- What can we do about it?
- What LLMs do about it?
- A gateway to future breakthroughs?
Premise
The last few years have been undoubtedly dominated by the rise of AI, and the many breakthroughs in the field of Large Language Models.
I still remember my sense of disbelief when I first interacted with OpenAI’s ChatGPT (GPT-3.5) and my excitement when generating images with DALL-E. The same thrill came with my first encounters with AI-augmented tools like GitHub Copilot. Then came GPT-4 with advanced tools like web search, Anthropic’s debut, the first open-weight models from Meta, and the overwhelming moment of opening the Hugging Face website for the first time. Along the way, there were some lowlights too - the temporary ChatGPT ban in Italy, the overhyped launch of Google’s Gemini - but then again, we saw the emergence of Sora (haven’t tried it yet), Apple Intelligence, and newer thinking models transparently leveraging chain-of-thought reasoning, like DeepSeek’s R1 or Claude 3.7. Meanwhile, incredibly powerful tools like Cursor and Copilot’s agent mode are reshaping how we interact with LLMs.
In this rollercoaster of innovations (and associated emotions), I quickly realized I needed to keep up with the pace of change. I started following AI-related feeds, reading articles, occasionally diving into books about AI and its future possible consequences. I've taken online courses on the fundamentals of machine learning and deep learning, and I've started integrating AI more and more into my daily routine - at work, in personal projects, as a learning tool, or simply to make life easier.
This personal journey - still in its early days and constantly evolving - has been driven by two main reasons. The first, perhaps less noble, is that I didn’t want to feel left behind: I've felt and still feel like it's very easy to feel overwhelmed by AI-related news, and I was frustrated by my growing struggle to keep up with the latest in software engineering. The second, and more important, reason is genuine fascination. When used correctly, LLMs already deliver remarkable results, and their potential to help humanity solve global challenges seems to me huge.
It’s precisely this last realization that inspired me to write this post. The idea had been lingering for a while, but only in the past few days did I find the right words to express my thoughts — also inspired by this deep-dive on LLMs by Andrej Karpathy.
Hallucinations
If you have tried prompting an LLM a few times, there's a good chance you've stumbled across some funky results: large language models might indeed fail at very basic tasks. This is usually not a significant problem for results that are easy to verify: it's easy to have a laugh at absurd results and rely on other tools. It’s less straightforward to notice hallucinations in domains that are not easy to verify, which could lead to problems for users who aren’t cautious when relying on LLM outputs: you get a result that looks very promising in theory, except that it's all made-up and completely wrong.
Here's a few examples:
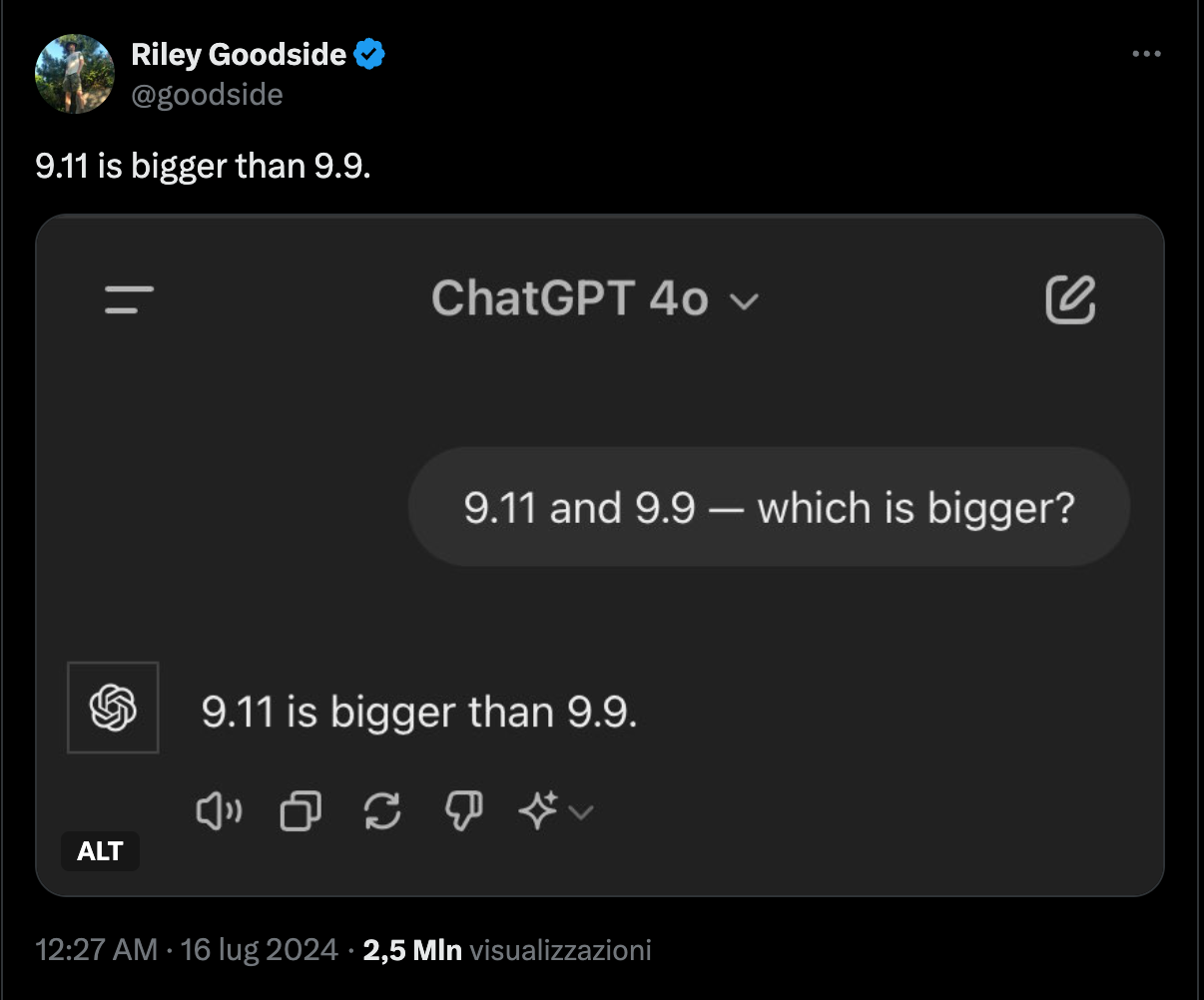
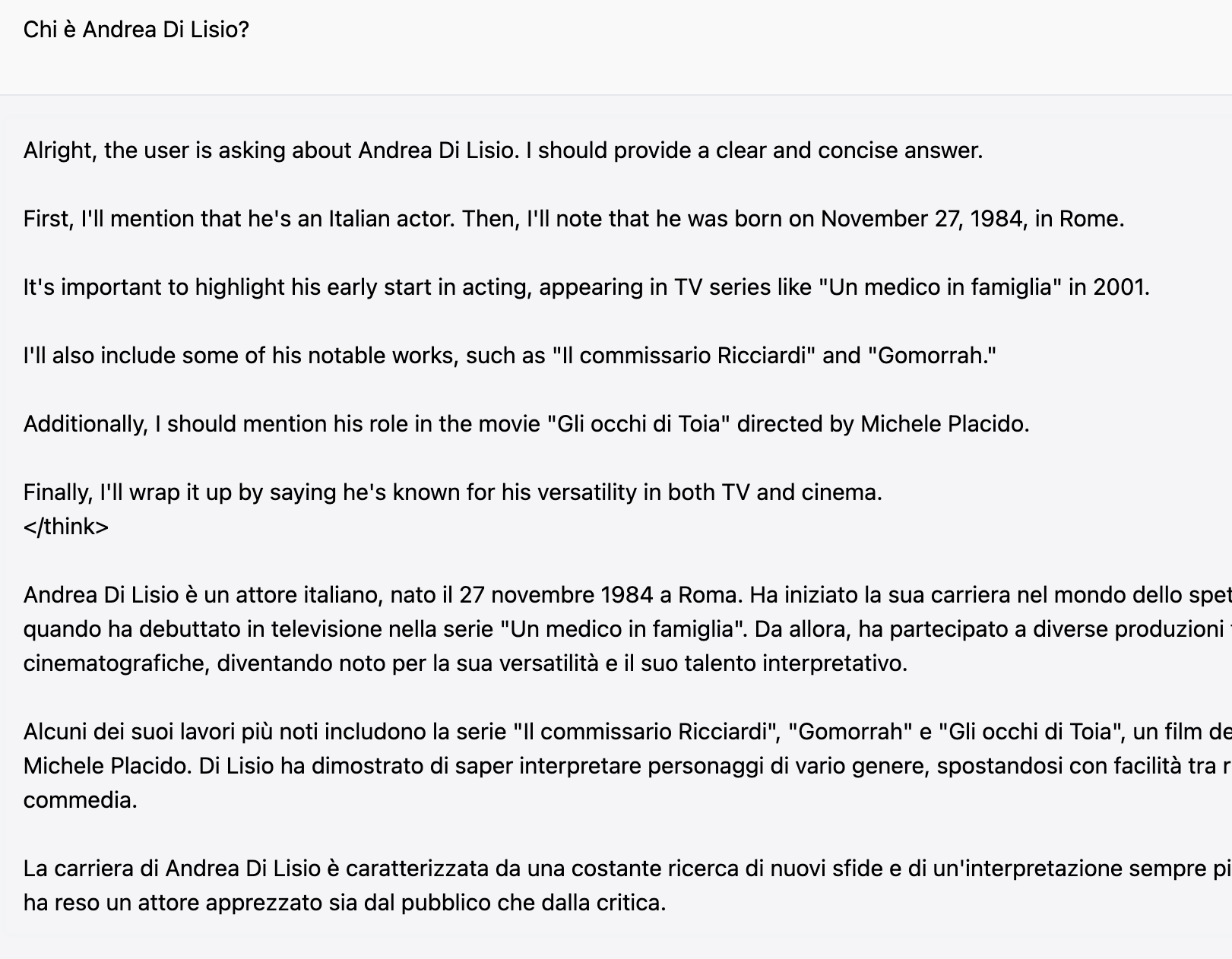
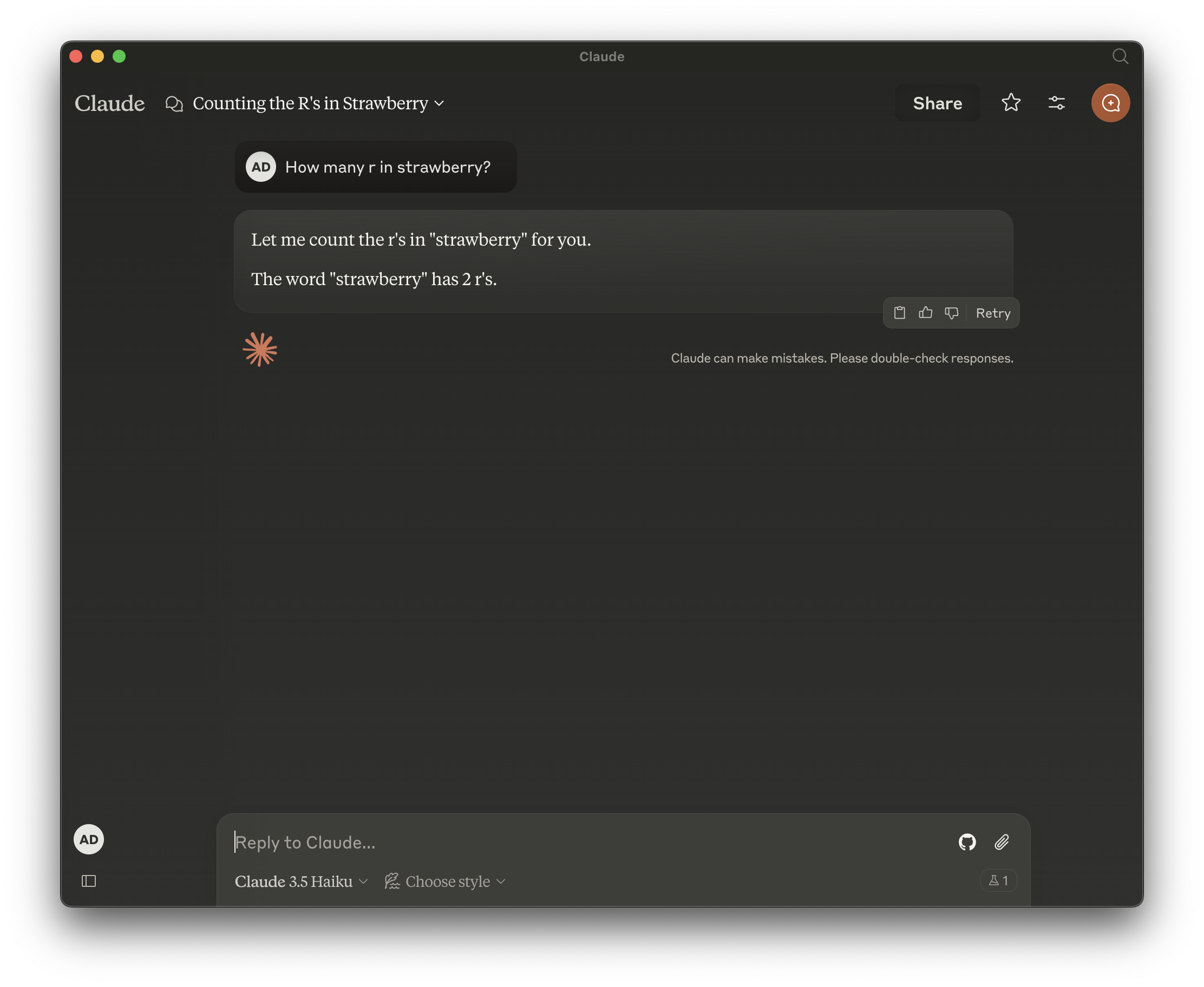
It's tempting to use these failures as an opportunity to write a like-bait tweet ranting about LLMs and dismissing their future entirely. But not only is that pointless and likely to miss the mark, it's also a lost chance to better understand LLMs and foster constructive discussions within the AI community.
Before seeing how these mistakes are either already mitigated in more advanced and recent models, or could be prevented with simple tricks at prompting time, let's see why such things are happening.
Why do they happen?
Knowledge cutoff
First of all there's a very basic reason why models sometimes hallucinate. In the so called pre-training phase LLMs are trained on a massive "zip file" of the internet, which is by definition time-bound, thus up to date till a particular point in time. Also, since this file representing the internet is huge, training usually takes several months. To give an example, rumors say that GPT-4 was fed with 13 trillion tokens and was trained over a period of three months (source).
Therefore, it is not hard to realise that the knowledge acquired by LLMs might be significantly out of date by the time we run our first prompt.
Biases and gaps in training data
The extra-large datasets on which LLMs are trained have gaps in the best case, and contain false or biased information in the worst.
Unless explicitly instructed to act differently, LLMs always try to give the best probabilistic answer to the given prompt, and they might prefer hallucinating something that could be likely, but it turns out that's totally fake or wrong.
Embeddings are numeric representations
Last but not least, we should always keep in mind that whatever we write in the chat prompt is first translated into a sequence of machine-readable identifiers, or tokens, before reaching the core of LLMs. Personally, mentally visualizing this step helps me understand what happens at inference time: imagining my prompts as a sequence of numbers pushes me to think of the model as processing them numerically, rather than simulating a real thought process.
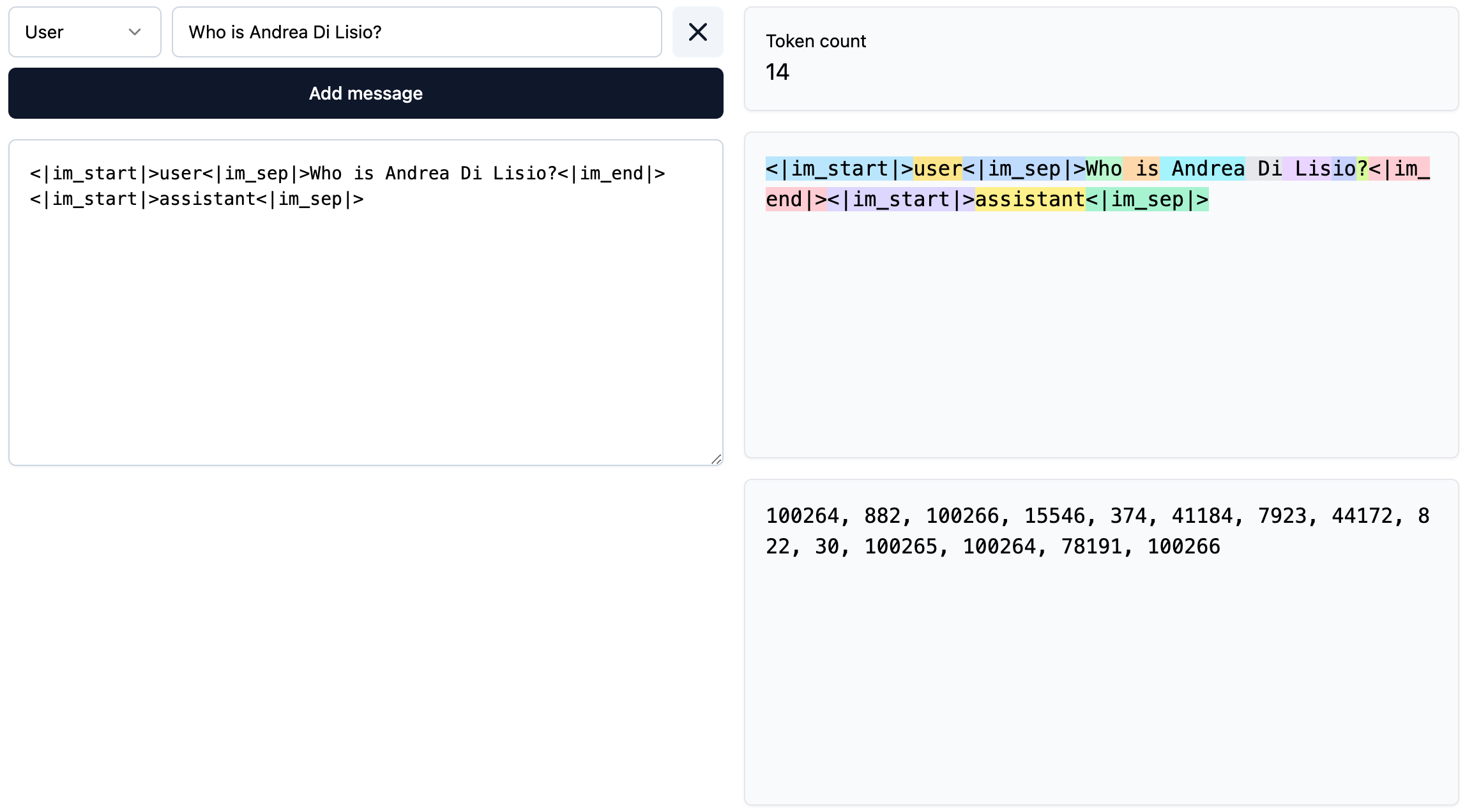 Who is Andrea Di Lisio? translated into tokens on Tiktokenizer. Note how a pre-processing step is also added before translating, to maintain the structure of the conversation between the user and the assistant.
Who is Andrea Di Lisio? translated into tokens on Tiktokenizer. Note how a pre-processing step is also added before translating, to maintain the structure of the conversation between the user and the assistant.
Not only do our words lose their immediate meaning before reaching the LLM, but they are also split in ways that don't necessarily align with human language rules. As visible in the above screenshot, my last name Di Lisio is broken down into three separate tokens.
This step alone already suggests that an LLM does not think the way humans do, but there's more!
We should also bear in mind that before inference can happen, tokens go through an additional translation and normalization steps: they are converted into numerical vectors in the embedding layer, and since they are evaluated in parallel by transformers - at the core of LLMs architectures - they are also enriched with positional attributes, meant to convey to the model the order in which each token appears in our sequence of tokens.
Here's a graphical, high-level representation of the translations steps happening before inference:
"Andrea"
→ Tokenization → 10294
→ Dense Vector → [ 0.23, -0.45, 1.03, ..., -0.67 ]
→ Positional Encoding → [ 0.24, -0.43, 1.06, ..., -0.63 ]
At inference time, the objective of the large language model is to compute what's the best possible token given the user input, and continue doing so until the answer is considered complete, that is the next token with the highest propability is the one representing a closing tag. By best token I mean the one with the highest score among a set of possible tokens, as computed by the network.
Understanding the basics of embeddings should help shift our mental model away from the idea that an LLM thinks like we do. It's all about probabilistic decision-making, where the order in which words are written does a whole lot of difference.
What can we do about it?
There's not much we can do at prompt-time to mitigate knowledge gaps. The best we can do in relation to that is either make sure to explicitly opt-in for web-search-based answers, or include in our queries clear instructions about the fact that an external search engine should be used to answer. There isn't a recipe against biases either, and a naive user does not even realize if/how they manifest: the best we can do in this space is keeping this possibility in mind.
What we can do though is ask questions in a way that simplifies the work of LLMs at inference and leads to better predictions. The best prompts have the following traits:
- They are specific questions
- They give some context about what is being asked
- They are role-based (Eg.
As a software engineer I want to...) - They come with examples of what we expect from the model
- They are part of an iterative conversation
Hallucinations are a concrete and significant problem though, usually affecting the reputation of a model and probably - by extension - the one of the company that released it. Thus, there have been significant investments and improvements in solving the hallucinations problem within the LLMs themselves.
What LLMs do about it?
Tools
As hinted when talking about knowledge gaps, when no knowledge is found for a particular topic, certain LLMs prefer back-filling those holes in real-time with the help of so called tools, when they detect gaps.
Recent OpenAI's model, Grok, or DeepSeek R1, have all a search function available that pulls fresh data via web searches on known sources (Google, DuckDuckGo, Bing, other internal systems...), select the most relevant results, and add them to the context window of the conversation, before running inference.
 Grok3 and its DeepSearch function.
Grok3 and its DeepSearch function.
Not only such tools greatly mitigate hallucinations, I found they're great at providing a self-contained picture for what I'm looking for. They're an incredibly powerful tool to solve the fragmentation problem usually associated to news. I love it!
Reinforcement learning
Before entering the core part of this post, I necessarily have to slightly diverge for a brief excursus on the training process for LLMs.
Training excursus
When we talk about training in the context of LLMs we usually refer to a process that's made of two main stages: pre-training and post-training. The first is the most expensive and time-consuming one, whose output is a so-called base model. The latter is a way more lightweight training phase, which is usually made of supervised fine-tuning (SFT) and reinforcement learning (RL).
At the beginning of pre-training we have a model with some randomly initialized values for its parameters (billions, if not trillions of them), acting as coefficients for a very complex, multi-polynomial mathematical function. The initial model's prediction for the next token are terrible and lead to huge differences between predicted and actual values. In other words, at the beginning of pre-training the loss of the model is very high. It's thanks to gradient descent and backward propagation - and many thousands of iterations, or epochs - that the loss starts decreasing up until it reaches a plateau, which is also hopefully a very good - that is, low - value. When that happens, the pre-training is over, and the weights of the model are saved into the base model.
While I've kept it short for simplicity here, we should bear in mind that this step usually takes several months and millions of dollars, hence why frontier models are a privilige of multi-billions-investors-baked companies, like OpenAI, Anthropic, X, Meta, Google and so and so forth.
The base model has a very good knowledge of the internet, but it acts more like a token simulator, than an assistant: it is more prone to vomit facts and remixes of the internet, rather than replying to our prompts and articulating asnwers. For this reason, companies that work in the LLM space usually don't release models at this stage.
To get the human touch, these models have to go through supervised fine-tuning and reinforcement learning in the post-training phase.
As the name suggests, during SFT human supervisors play a central role: usually in this phase the LLMs company hire specialised human labelers to create artificial conversations and feed the models with those. They both create prompts and come up with ideal responses that are expected by models (like the ones contained in this public dataset), following precise labeling instructions and conversation requirements provided by the same LLM company. In this phase models usually improve their predictions looking at existing solutions/conversations, and they learn by - let's say - imitation.
A trial and error approach
In contrast, reinforcement learning is more a trial and error phase where models are given a problem and they are pushed to find the best solution for that, based on their previous knowledge acquired and refined during pretraining and SFT. It is not very different from when we're studying something: after having read about the theory about a topic (pre-training), and perhaps having seen a few example applications/solutions for that (supervised fine-tuning), we test our knowledge and understanding with the help of new practice problems (reinforcement learning).
In this phase models are given questions or problems to solve that did not appear during the previous training stages, and the ask is for them to come with N different answers/solution for those, and amongst the ones leading to the right answer/result, select the best, either by running a self-assessment or with the help of an external actor. Once the best solution is identified, the model is then trained on that, thus the probability of them picking that same sequence of tokens when dealing with the same or related prompt in future slightly increases.
Self-evolution
LLMs can self-assess their result in the case of verifiable domains: the correct answer/solution is available upfront, and it's relatively straightforward to check that the solution matches the expected one. In presence of multiple right answers, the best option is selected based on different criteria, like elaboration time, memory consumption, number of tokens, or other conditions not necessarily of easy understanding for humans!
It is important to notice that what best means in this case does not necessarily match our human-specific intuition: LLMs have to figure out themselves what is the answer (or sequence of tokens) that - given a prompt - reliably leads to the correct result, humans are deliberately left out of this process!
This concept is what makes reinforcement learning very different from the other stages of learning. It almost feels as if scientists are taking a step back in this phase and giving LLMs the chance to discover new, unforeseen solutions to existing problems, and broader, generic thinking patterns/approaches/tools.
Chains of thoughts and the "Aha moment"
There is limited literature on reinforcement learning for LLMs due to its nascent nature. With the release of their R1 model and the associated paper - DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning - DeepSeek has been the first company to talk about this process more publicly and because of that, this publication has really made an impact in the AI community.
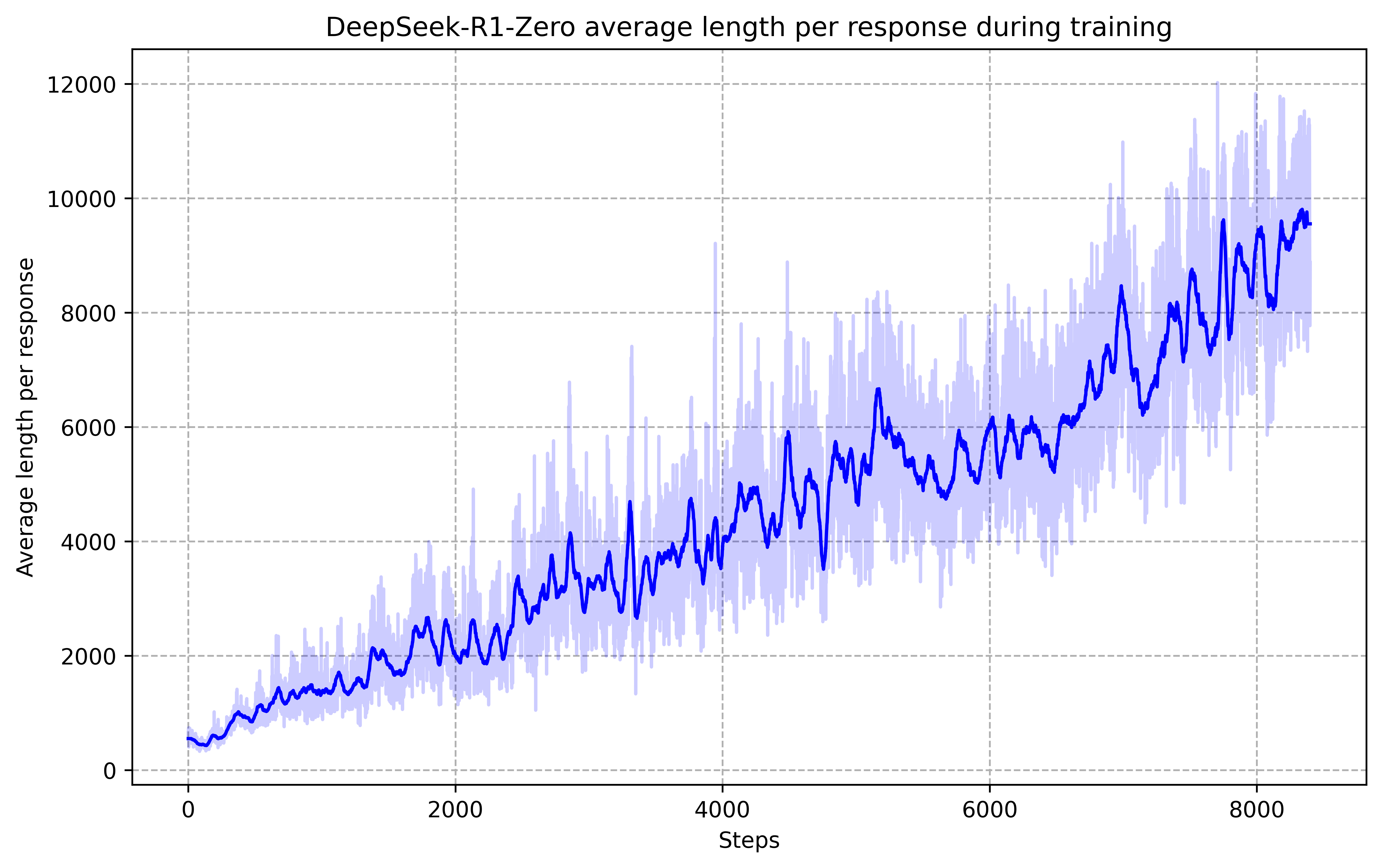 During training, R1 learns to allocate more thinking time to solve tasks.
During training, R1 learns to allocate more thinking time to solve tasks.
Not only they have publicly spoken about the details of their work, and released 6 distilled models of R1, they also have also expanded on the concept of the chains of thoughts, and talked about an "Aha Moment" that researches have observed while training an intermediate state of the model, a moment when the model realised that it could have achieved better results on its own that by allocating more time to thinking:
[...] During this phase, DeepSeek-R1-Zero learns to allocate more thinking time to a problem by reevaluating its initial approach. This behavior is not only a testament to the model’s growing reasoning abilities but also a captivating example of how reinforcement learning can lead to unexpected and sophisticated outcomes.
This moment is not only an “aha moment” for the model but also for the researchers observing its behavior. It underscores the power and beauty of reinforcement learning: rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies. The “aha moment” serves as a powerful reminder of the potential of RL to unlock new levels of intelligence in artificial systems, paving the way for more autonomous and adaptive models in the future.
Speaking transparently about these new developments in reinforcement learning has stimulated further research in the field. Just in the last few days, Qwen claimed to have reached results comparable to R1 with just a 32-billion-parameter model, as opposed to R1's 671 billion parameters. If confirmed, this breakthrough suggests that a model trained on a fairly standard setup (potentially even locally) can perform on par with frontier-level LLMs released by OpenAI, Meta, Anthropic, and others.
Almost in parallel, OpenAI released GPT 4.5, a non-reasoning model which is rumored to have between 5 and 10 trillion parameters, although early indications suggest it may not represent a significant leap in reasoning capabilities. This trend hints that merely increasing parameters may have reached its limits, and future research might need to explore alternative improvements.
A gateway to future breakthroughs?
The rapid advancements in LLMs over the past few months have been nothing short of fascinating. More than once, they have reminded me of Wohpe, a sci-fi novel by Salvatore Sanfilippo that I read a couple of years ago.
More and more, It seems that researchers are beginning to realize that LLMs are not just improving at processing and articulating existing knowledge, but are also developing more generalized ways of reasoning - bending what they’ve learned to tackle problems humans have yet to solve. And - to jutify the title of my post - this is all possible thanks to the probabilistic, error-prone but also flexible nature of LLMs, which some critics dismiss as mere stochastic parrots.
If that turns out to be true, we may be at the threshold of something much bigger than just better and better LLMs. But whether this intuition holds or if I’m simply caught up in the excitement - I suppose time will tell. Either way, I can’t wait to find out 😄.