on
Yet another connection reset
 A sort-of accurate representation of a scissor cutting connections to my Kestrel server, as hallucinated by OpenAI
A sort-of accurate representation of a scissor cutting connections to my Kestrel server, as hallucinated by OpenAI
This is meant to be a short post about a bad day I had a work recently.
Initial context
My team had to expose a new API over gRPC from one of our .NET Core backend applications (from now on named Service C) to be consumed by a downstream service (from now on named Service A), similarly implemented using .NET core. The 2 services had to communicate over HTTPS within our Kubernetes cluster.
While we're slowly stepping into the magic world of service meshes (thanks to LinkerD), historically we have been solving all these connectivity-related challenges with the help of Envoy, deployed as sidecar in our application pods. Envoy was originally introduced as a drop-in technology to implement gRPC load-balancing, and a kind-of transparent solution for TLS termination, with or without mutual TLS. It's a widely adopted technology in my company, and we keep using it, especially on existing applications serving live traffic, like Service C.
However, oddly enough, in our Service C Envoy was used only as egress to communicate with downstream services. Why? Maybe at the time Service A was integrated with our gRPC API, we had a tight deadline for going live, and considering that Service A's gRPC .NET client was capable of load balancing, we probably preferred taking the shortest route and decided to not use Envoy at all as ingress, but simply have our .NET core application accepting requests over HTTPs and be responsible for TLS termination... Or, at least, this is how I explained it to myself.
This is more or less the initial setup we had:
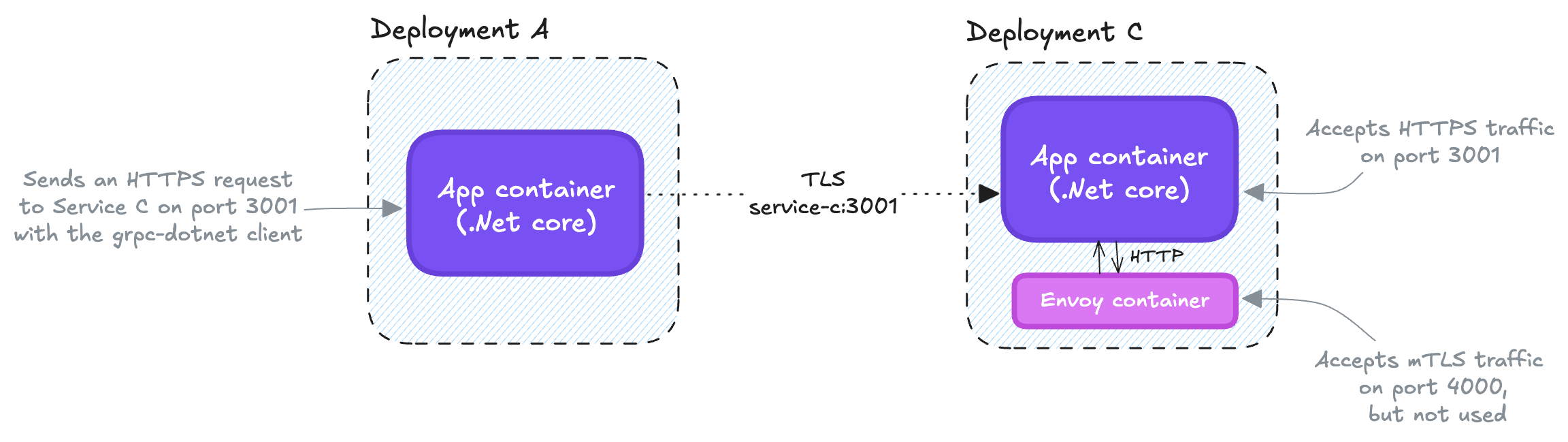 Service A calls Service C over HTTPS. At this point it's not clear what's the benefit of using Envoy on Service C...
Service A calls Service C over HTTPS. At this point it's not clear what's the benefit of using Envoy on Service C...
Moving on
Then, a few days ago my team had to onboard a new service, namely Service B, over the same gRPC API. In this case, also because we had a mutual TLS requirement, I suggested to start using Envoy also as ingress and TLS terminator. So, I did the following changes, mainly:
- I changed our .NET app to start accepting requests on HTTP only;
- I added a new TLS-only ingress on our Envoy sidecar, to be used by Service A;
- I basically kept the existing mTLS ingress on Service C as it was, and I routed the new traffic coming from Service B onto it.
An important requirement for the above changes was that nothing should have changed from the perspective of Service A, to not impact live traffic. The new setup looked like something like this:
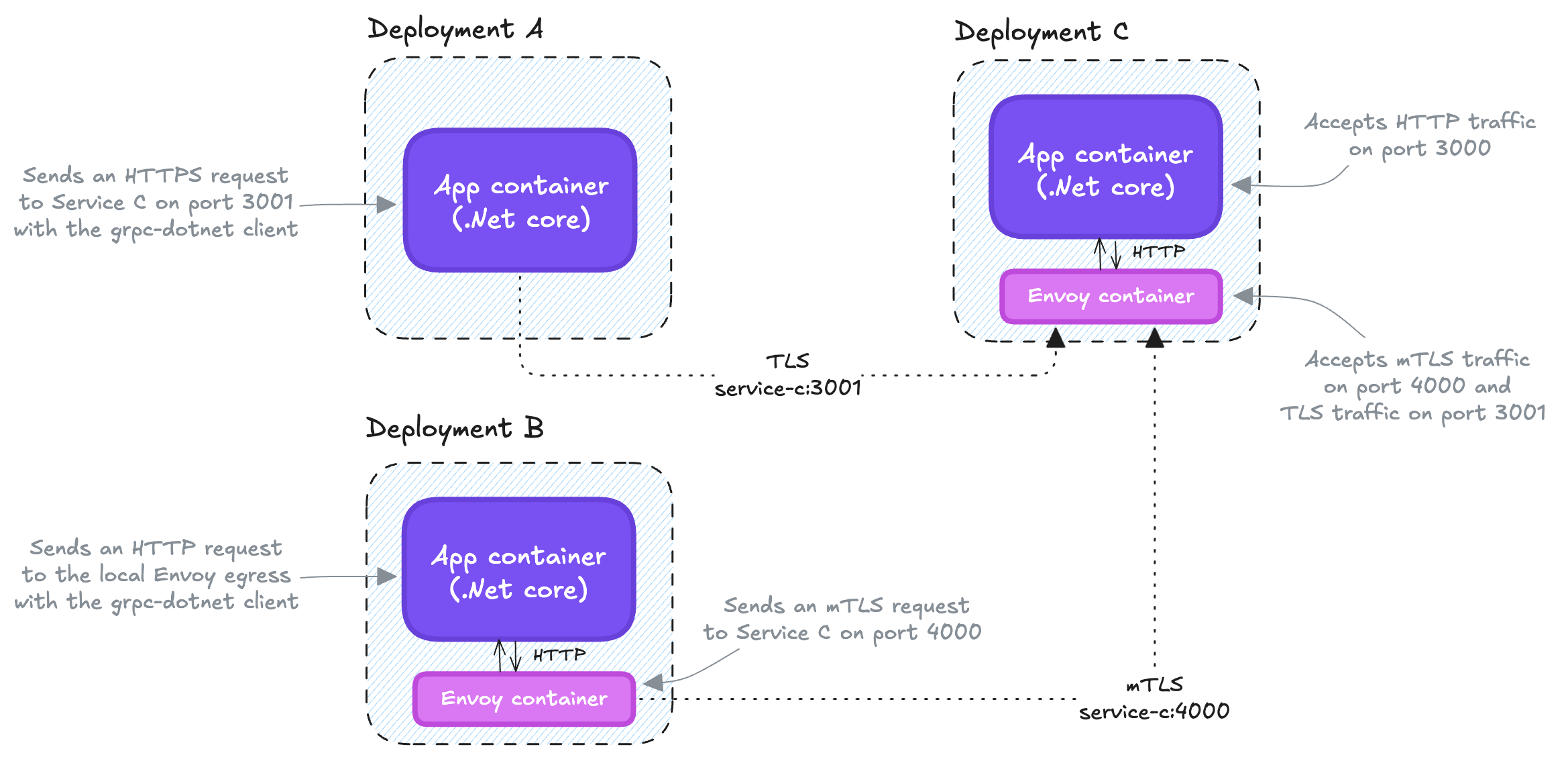 Both Service A and Service B reach Service C via its Envoy ingress. The .NET core container within Service C expects plain HTTP requests only.
Both Service A and Service B reach Service C via its Envoy ingress. The .NET core container within Service C expects plain HTTP requests only.
Everything looked linear and clear on paper, but it was not working 😅.
All that glitters is not gold
I did not face particular problems with Service B and C, it was the interaction between A and C that turned out to be particularly painful.
Application-Layer Protocol Negotiation (ALPN)
The first error I've encountered was very explicit and therefore quite straightforward to solve:
Error starting gRPC call. HttpRequestException: Requesting HTTP version 2.0 with version policy RequestVersionOrHigher while server offers only version fallback.
After some digging, it turned out that the ingress on Service C was only offering HTTP/1.1 as available protocol by default, whereas the .NET client included in Service A could only communicate using HTTP/2.
I solved this problem by declaring explicitly the ALPN protocol that the ingress on Service C was offering, on the Envoy configuration*
listeners:
- name: tls_internal_ingress
address: 0.0.0.0
port: 3001
tls:
enabled: true
alpn_protocols:
- "h2"
certs_mount_path: /certs/
mtls:
enabled: false
o11y:
enabled: true
http:
kind: server
virtual_hosts:
domains:
- "*"
routes:
- match: { prefix: "/", grpc: { } }
route:
cluster: signup_plus_grpc_cluster
* note that the above configuration snippet mixes Envoy's native configuration syntax with a simple abstraction layer that we build on top of Helm.
Alternate schemes
The second problem I've faced is the one that made me mad for a few hours, and the reason why I've decided writing this rant post. This one got me crazy because all I had from the logs of the Envoy ingress on Service C was a Connection reset error with a vague upstream reset: reset reason: remote reset, transport failure reason: error message.
After a few hours trying to explain myself what I had done wrong that day to deserve such destiny, I noticed that Envoy logs were mentioning a specific UR response flag. After some back and forth on Envoy's public documentation (sigh), I've found the following bits:
UpstreamRemoteReset | UR | Upstream remote reset in addition to 503 response code.
Which convinced me that the problem could only have been on the .NET application within Service C. So I've moved on in that direction, and I've discovered something else:
...
service-c-5c9f4f979-kbpdm envoy-proxy ':method', 'POST'
service-c-5c9f4f979-kbpdm envoy-proxy ':scheme', 'https'
service-c-5c9f4f979-kbpdm envoy-proxy ':authority', 'service-c.verification.svc.cluster.local:3001'
...
The weird thing was that the request originating from the grpc-dotnet client of Service A was left as-is from the Envoy ingress on Service C. More specifically, the https scheme was not transformed after the TLS termination offered by Envoy.
My thinking got a confirmation also from Envoy docs:
For HTTP/2, and HTTP/3, incoming :scheme headers are trusted and propagated through upstream
But... that was probably unexpected from the perspective of the .NET app within Service C because it was accepting only requests in plain...
And... finally! I realized that the AllowAlternateScheme property of Kestrel - the technology behind the .NET gRPC server on Service C - being set to false by default was the issue in this case. Toggling that flag to true put an end to my sorrows! 🎊
PS: in hindsight, another approach could have been to take over the default scheme manipulation on Envoy, but at that point my brain was fried and the last thing on earth I wanted to do was fighting again with Envoy... That being said, changing this default behavior on Envoy is probably a better choice, to not pollute the application code with networking-specific details.